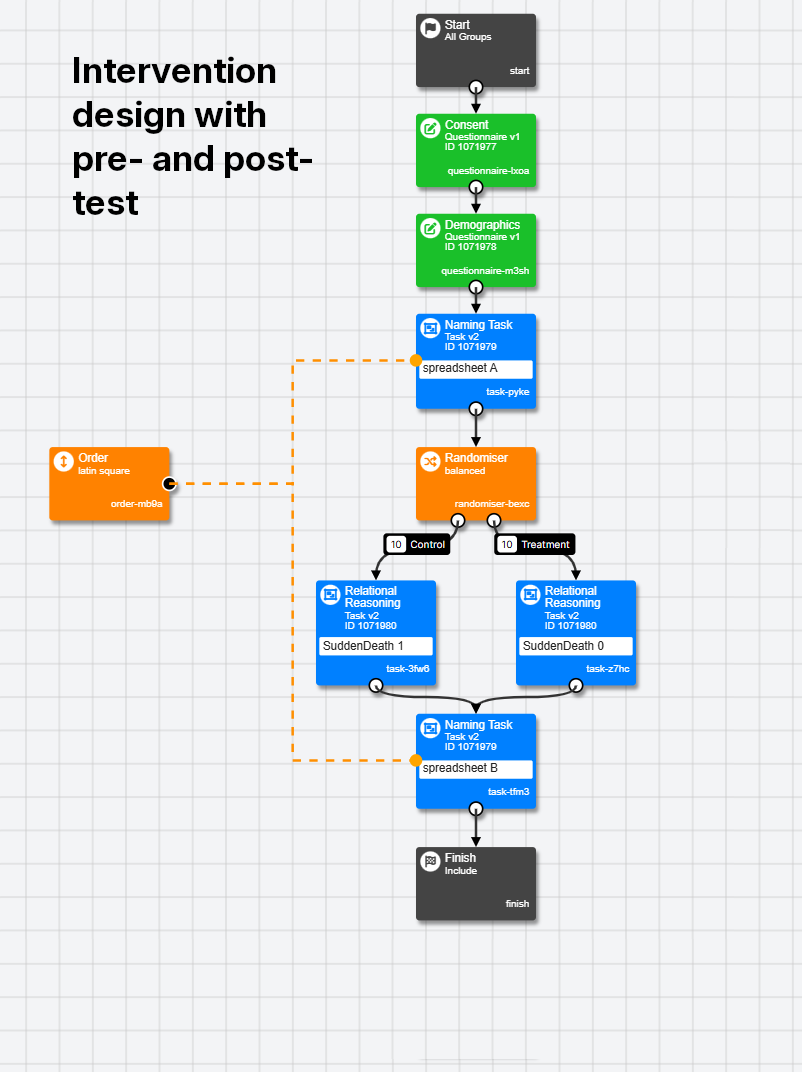
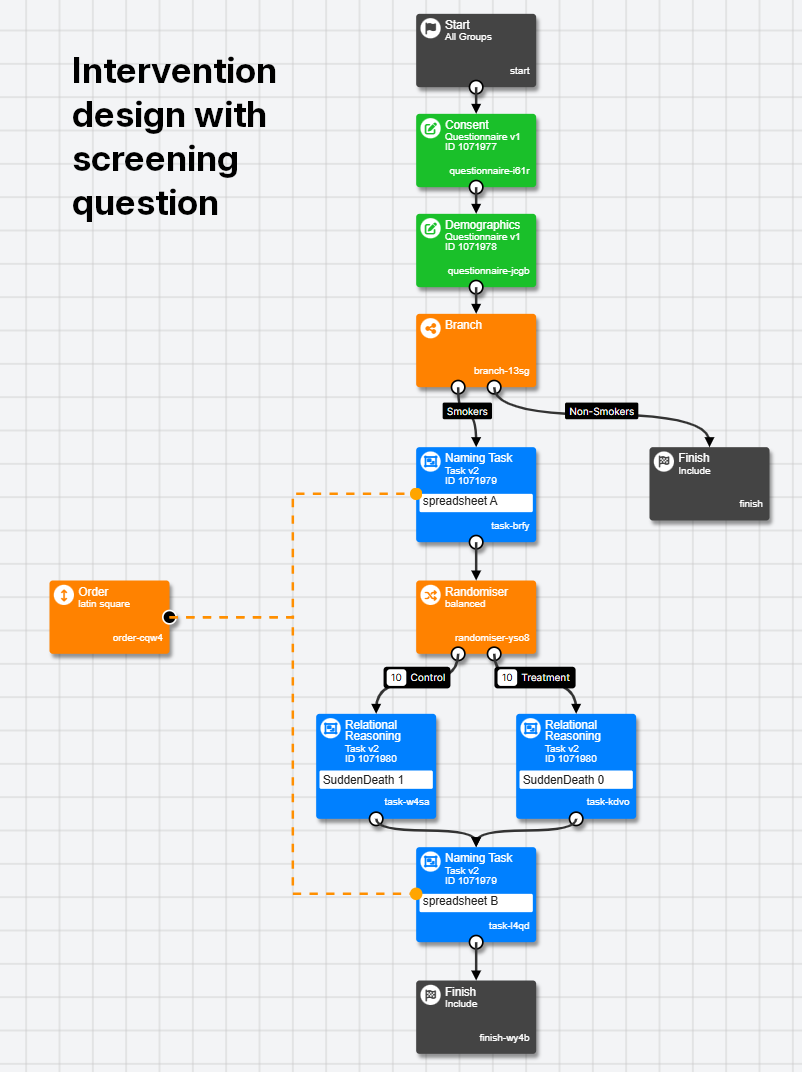
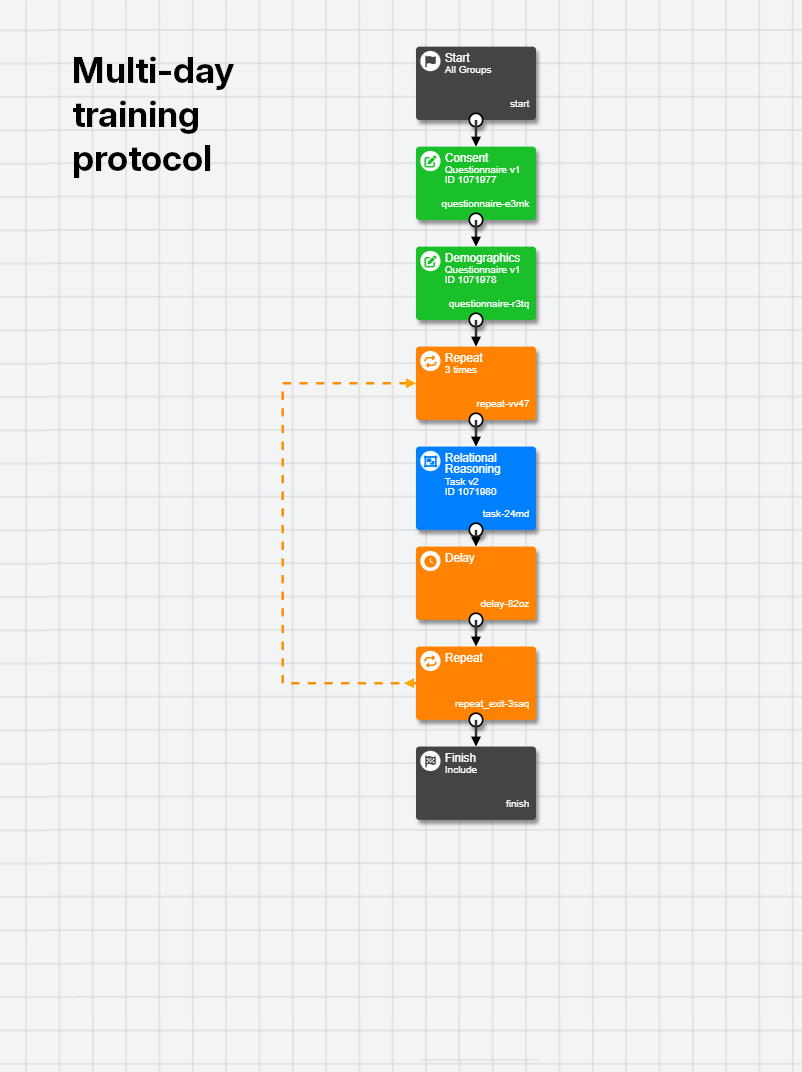


Book a Demo
Let us show you Gorilla
Are you a little stumped on how to take your research online?
Come join us for a short and friendly demonstration that will help to get you off the ground quickly and confidently.
" Thank you for the demo today! It was so helpful to understand how much Gorilla can do to help our students, staffs and technicians. "
Book Your Demo Today