This data provides guidance on how to access your participant data from your experiment.
All data you collect is owned by you. Data can be downloaded from the Data tab in the Experiment Builder Tool.
Respondent data is stored by version, meaning that if you make changes to your experiment during data collection, data from respondents who completed the earlier version of the experiment will be stored separately from data from later respondents.
To download your data, use the Version Picker to select the version of your experiment that your participants completed.
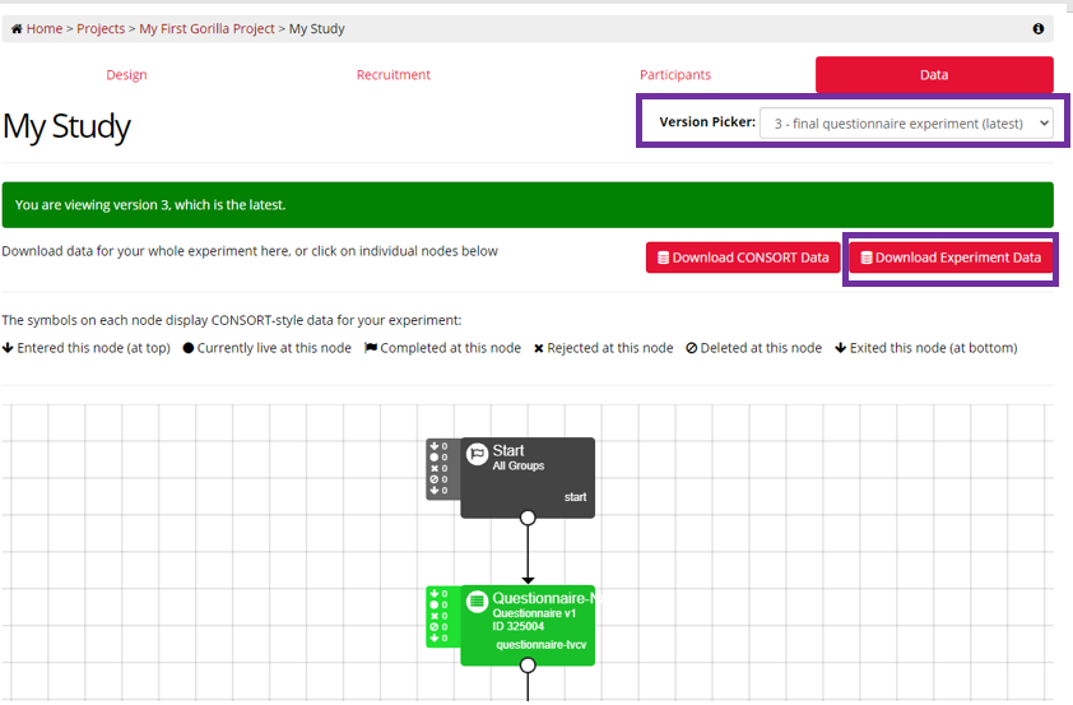
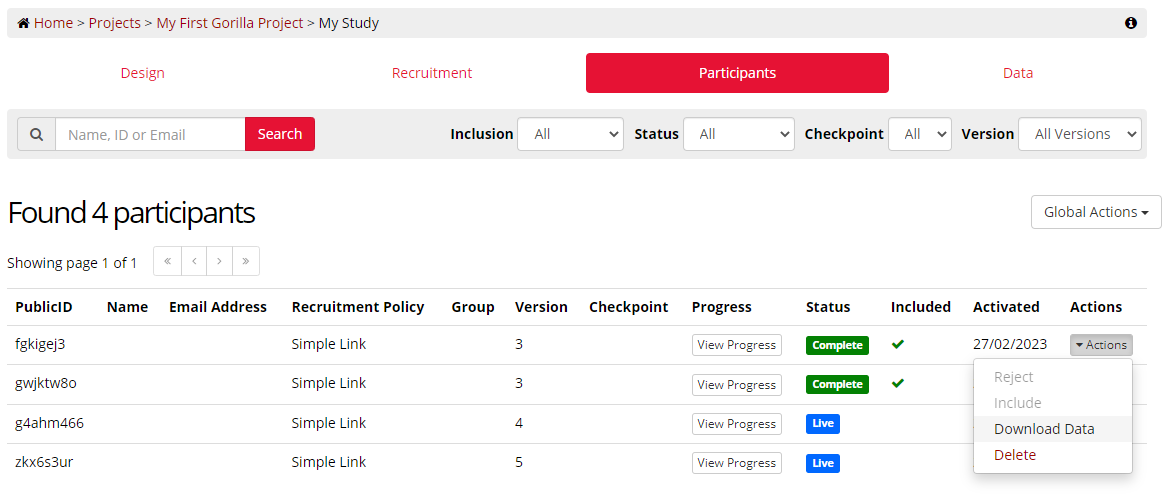
You can find out which version of your experiment participants completed from the Participants Tab, as shown below:
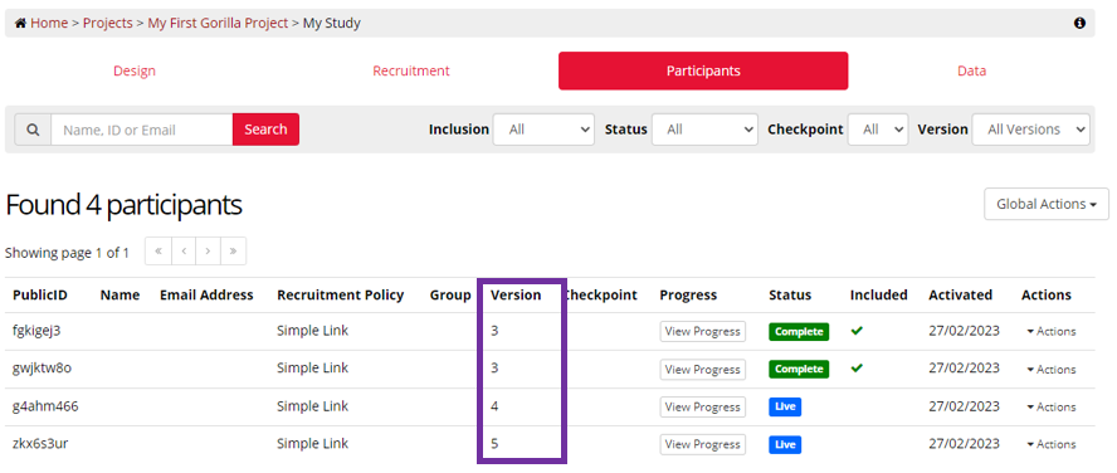
Once you have selected the correct version, you can choose to download your data by-node, or all together in a zip file. We also have a useful guide on Combining your data.
To download all your data, click the button labelled Download Experiment Data.
To download data by node, click on that node.
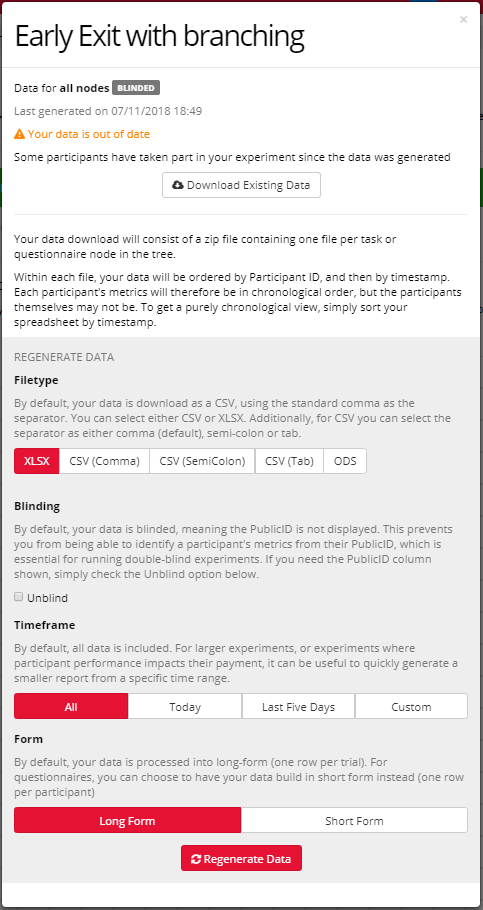
You can then select what file type you’d like your data to be downloaded in (XLSX, CSV (comma, semicolon or tab delineated), or ODS).
You have the option to unblind your data, which displays Public IDs along with Private IDs in your metrics, meaning that your participants could potentially be identified. You can also choose to display your questionnaire data in short form. We have a useful guide on Data Format, and how this looks.
You can also select the time period of data you’d like to collect.
Task data will be generated in Long-Format (one row per trial). For Questionnaire data, you have the option to download data in either Long-Form or Short-Format (one row per participant). You can follow our guide on how to clean and transform your data into Short-Form using R.
Then click Generate. Generating data does not affect your token number, and you can generate your data an unlimited number of times.
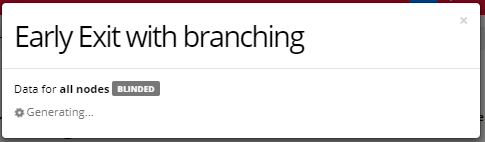
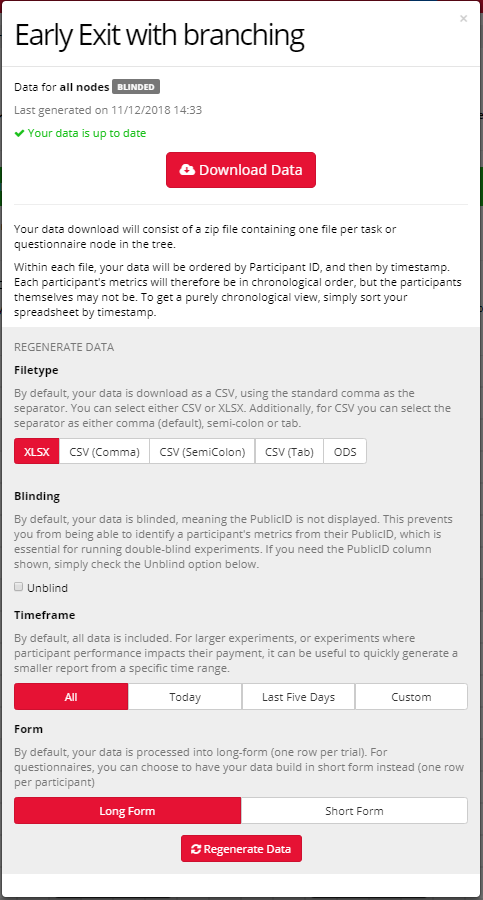
Once your data has been generated, click Download. If your data takes longer than 24 hours to generate, please Contact Us!
If your data file is blank, check that participants have completed the version you’ve downloaded data for, and that these participants have been included.
To find out how to understand and analyse your data, check out out Gorilla data analysis guide
If you wish to download the data from a specific participant, you can do this via the Participant Tab. To access all data from all participants, see the downloading all data section of this guide.
To download the data from a single participant, navigate to the Participants Tab of the Experiment Builder, and click the Actions button, and select 'Download Data'. You can only download the data from participants that have Completed the experiment, or have been manually included in the dataset.
Once you click Download Data, you will be able to choose the format and filetype of the data, and whether you would like to Unblind the data.
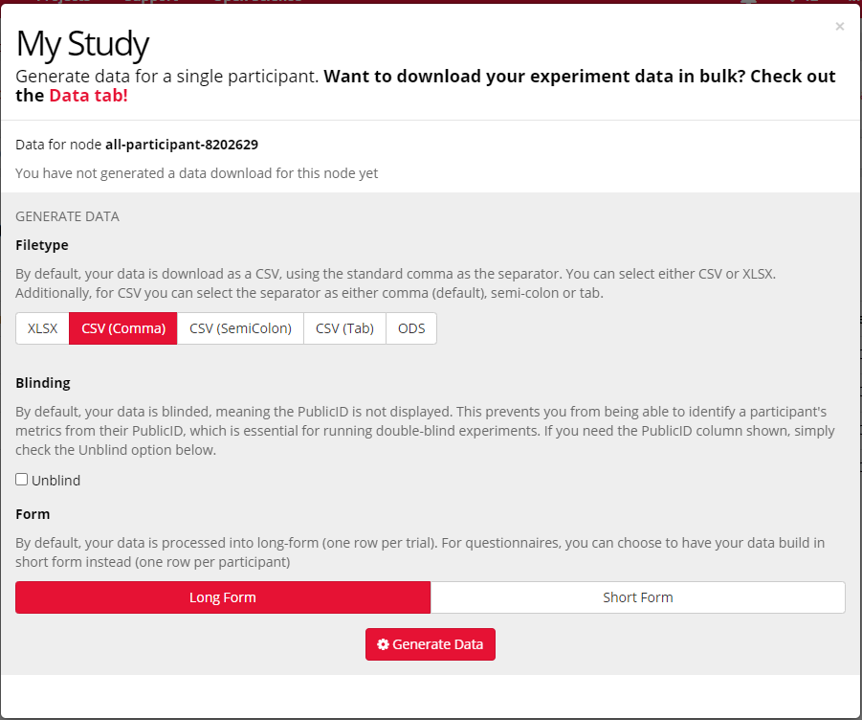
It's good practice to keep performance data, demographic data and identifying data separate, which is why we give you a separate file for each node. You can combine data from tasks into a single file, and data from questionnaires into a single file.
We have a couple of guides to help you combine your data. We have created an R Studio walkthrough and a video guide in Excel which provide more details on how to combine your data files. You can also see an example of how to do this with data from a real experiment, and download the relevant R script, in this Gorilla Academy case study.
Everything you need to know about understanding your data can be found in our Data Analysis guide.
Check it out to understand: